王选所学生参加神经信息处理系统大会NeurIPS 2025
发布时间:2025-12-26
发布时间:2025-12-26
第39届神经信息处理系统大会(NeurIPS)于2025年11月30日至12月7日在墨西哥城和美国圣地亚哥两地同时举行。神经信息处理系统大会创立于1987年,是CCF A类人工智能领域国际顶级会议。今年大会的主渠道共收到21575篇有效投稿,最终收录5290篇论文,录用率为24.52%。
北大王选所池昊哲、林宇辰、罗宇轩、王浩翔、周屹霄等学生发表论文并前往美国圣地亚哥参加了本次会议(按照第一作者姓氏笔画顺序排序)。
1. 通过卡尔曼控制增强基于流的图像编辑的一致性 ( Enhancing Consistency of Flow-Based Image Editing through Kalman Control )
基于流的生成模型已在图像生成与编辑任务中得到广泛应用。对于指令驱动的图像编辑而言,确保编辑操作严格限定在目标区域、同时保持非目标区域与原图一致性至关重要。然而,现有方法往往无法有效避免编辑过程在非目标区域产生意外偏移。我们首先指出,这一限制的根源在于编辑步骤中的误差逐步累积,并在多个编辑阶段的历史信息融合时被放大。为此,我们将图像编辑重新表述为一项控制问题,并引入卡尔曼滤波器以整合历史编辑轨迹。
基于这一思想,我们提出了 Kalman-Edit,一种能够从早期轨迹中重用细粒度细节的编辑算法,从而显著提升最终结果的结构一致性。此外,我们构建了一种基于近似向量场的快速编辑管线,实现高效的场速度估计。在多个数据集上的大量实验表明,Kalman-Edit 在编辑质量与一致性方面均显著优于现有的最新方法。

池昊哲
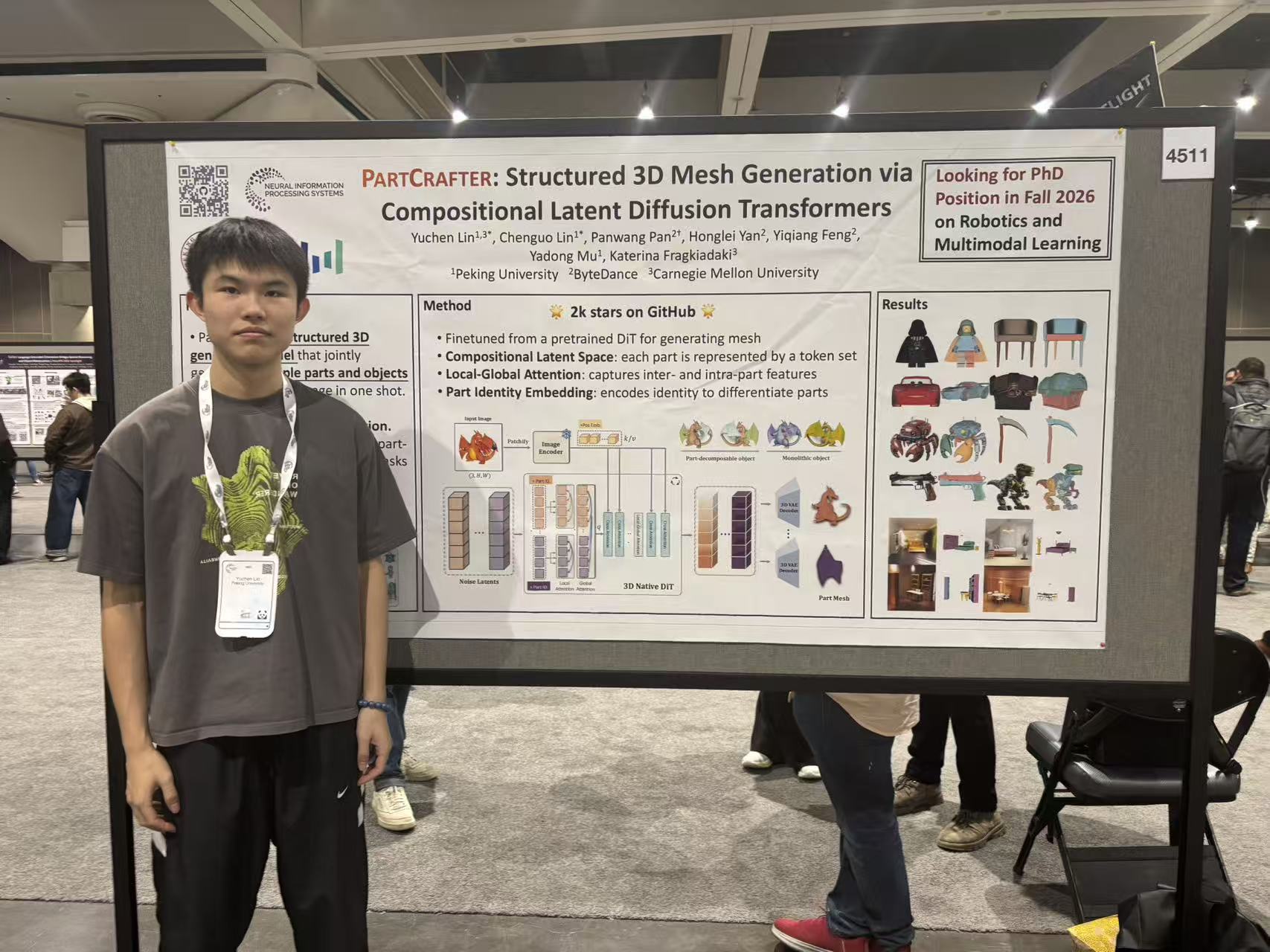
2. PartCrafter:通过组合式潜在扩散 Transformer 的结构化 3D 网格生成 ( PartCrafter: Structured 3D Mesh Generation via Compositional Latent Diffusion Transformers )
我们提出 PartCrafter,这是首个能够从 单张 RGB 图像 同时合成多个具有语义意义且在几何上彼此不同的 结构化 3D 网格(3D meshes) 的生成模型。与现有方法不同,它们要么仅生成整体式(monolithic)的 3D 形状,要么采用两阶段流程(即先对图像进行分割,再重建每个分段),而 PartCrafter 采用统一的、组合式(compositional)的生成架构,无需依赖预先分割的输入。在单张图像的条件下,它可以 同时对多个 3D 部件进行去噪(denoise),从而实现对单个物体及复杂多物体场景的 端到端、具备部件意识(part-aware) 的生成。PartCrafter 构建于一个经过预训练的 3D 网格扩散 Transformer(DiT) 之上,该模型在完整物体上训练,因而可以直接继承其预训练权重、编码器与解码器。
与此同时,PartCrafter 提出了两项关键创新: (1)组合式潜在空间(compositional latent space):其中每个 3D 部件都由一组相互解耦(disentangled)的潜在 token 表示; (2)分层注意力机制(hierarchical attention mechanism):使得信息能够在部件内部以及所有部件之间结构化流动,在生成过程中既保证了全局一致性,又能保留部件级别的细节。为了支持部件级监督,我们从大规模 3D 物体数据集中挖掘并整理了一个新的 部件标注数据集。
实验结果表明,PartCrafter 在可分解的 3D 网格生成方面优于现有方法,甚至可以生成输入图像中不可直接观察到的部件,展示了 部件感知生成先验(part-aware generative priors) 在 3D 理解与合成中的强大能力。

罗宇轩
3. MMMG:面向知识图像推理生成的大规模、多学科、多层级生成基准 ( MMMG: A Massive, Multidisciplinary, Multi-Tier Generation Benchmark for Text-to-Image Reasoning )
为了在这一进阶领域提供标准化的评估体系,北京大学王选所连宙辉副教授团队与微软亚研院在 NeurIPS 2025 上提出了首个面向 T2I 多模态推理的大规模评测基准——MMMG (Massive, Multidisciplinary, Multi-Tier Generation Benchmark)。它包含 4,456 个测试样例,覆盖数学、物理、生物、历史等 10 大学科,难度横跨学前至高中 6 个教育层级,旨在全面评估模型在多模态语境下的实体知识、属性绑定及复杂逻辑推理能力。针对传统指标无法量化知识正确性的痛点,团队提出了基于知识图谱(KG)的新型评测指标 MMMG-Score。该指标包含两个核心维度:在知识保真度(Knowledge Fidelity)方面,通过 VQA 模型提取结构化场景图并计算其与真实知识图谱的图编辑距离(GED),精准量化实体存在性、指代关系及功能逻辑的一致性;在视觉可读性(Visual Readability)方面,则通过图像分割数估计图像的视觉清晰度,以排除低质量生成对推理评估的干扰。
实验表明,现有的文生图模型在面对需要逻辑推理和知识内嵌的图表时,往往会出现文本遵循能力较差、知识实体刻画不明、或关系逻辑错误的情况。以“电机原理图”生成为例,GPT-4o-Image-1 虽然能推理出磁铁、线圈、定子转子等知识概念,但在刻画马达的物理连接、磁极方向等功能性指代关系时出现严重逻辑崩坏。这也证实了单纯的视觉逼真度并不等同于知识推理能力。
为此,团队进一步提出了 Baseline 模型——FLUX-Reason。该模型将知识推理过程前置于文本端,利用大语言推理模型的思维链(CoT)指导知识布局与关系刻画,并在收集的 16,000 条训练集上对 FLUX.1 [dev] 进行了微调。通过实验,团队发现基于DeepSeek模型的显性思维链在指导图像生成时优于 OpenAI-o3 给出的隐性、概括式思考。这一发现为未来开发具备强推理能力的文生图模型提供了重要参考。
林宇辰
4. 通过隐私文本中介生成高分辨率的隐私保护图像( Synthesize Privacy-Preserving High-Resolution Images via Private Textual Intermediaries )
生成既具备高保真度又满足差分隐私(DP)约束的合成图像,是在不泄露个体隐私的前提下共享和分析敏感视觉数据的一条重要途径。然而,现有的 DP 图像生成方法往往难以同时兼顾高分辨率与对原始数据结构的忠实保留。为此,本文提出一种全新的高分辨率 DP 图像生成框架 —— 通过私有文本中介的图像生成(Synthesis via Private Textual Intermediaries, SPTI),能够以极低使用成本生成高质量的 DP 图像。
SPTI 的核心思想是将 DP 生成的难题从图像域迁移至文本域:通过 DP 文本生成技术替代在图像域进行高维噪声扰动的过程。具体而言,我们首先实现隐私图像与文本表示的跨模态对齐,使得生成的 DP 文本在被转化为图像后,能够逼近原私有数据的分布;随后使用预训练的文生图模型从 DP 文本中重建图像。值得强调的是,SPTI 无需任何模型训练,全方法完全依赖现有大模型的推理即可完成。
在私有数据集场景下,SPTI 生成的图像质量相比既有 DP 方法取得显著提升。在 LSUN Bedroom 数据集上,SPTI 在 ε = 1.0 时达到 FID = 26.71,显著优于 Private Evolution 的 FID = 40.36。在 MM-CelebA-HQ 数据集上,SPTI 的 FID 为 33.27(ε = 1.0),相较 DP 微调方法的 57.01 亦有大幅改善。

王浩翔
5. 用于大规模图链接符号预测的 SignFlow 二部子图网络( SignFlow Bipartite Subgraph Network For Large-Scale Graph Link Sign Prediction )
符号二部图广泛应用于社交网络和推荐系统等多个领域,其中的链接符号预测最近已成为一项关键挑战。然而,与二部图可扩展性相关的显著时空复杂度带来了巨大挑战,特别是在大规模环境中。
为了解决这些问题,本文提出了 SignFlow 二部子图网络(SBSN)。该网络通过一种集成了新颖消息传递模块的启发式子图提取方法,平衡了训练内存的亚线性增长,并通过节点特征蒸馏模块实现了最优的推理效率。
我们的子图采样方法通过聚焦于目标链接周围的邻域来减小图的大小,并采用优化的有向消息传递机制来聚合关键结构模式。这种机制使得 SBSN 能够高效地学习对准确符号预测至关重要的丰富局部结构模式。此外,为了克服基于子图采样的模型在推理阶段的低效性,SBSN 在第一阶段训练后引入了节点特征蒸馏模块。该模块将子图特征蒸馏为节点特征,在保留子图丰富结构信息的同时实现了快速推理。
实验表明,SBSN 在中大规模数据集上均表现出卓越的性能,能够高效管理内存和计算资源,使其成为广泛应用的可扩展解决方案。SBSN 的代码实现已公开在 https://github.com/WICTSA/SBSN。
周屹霄