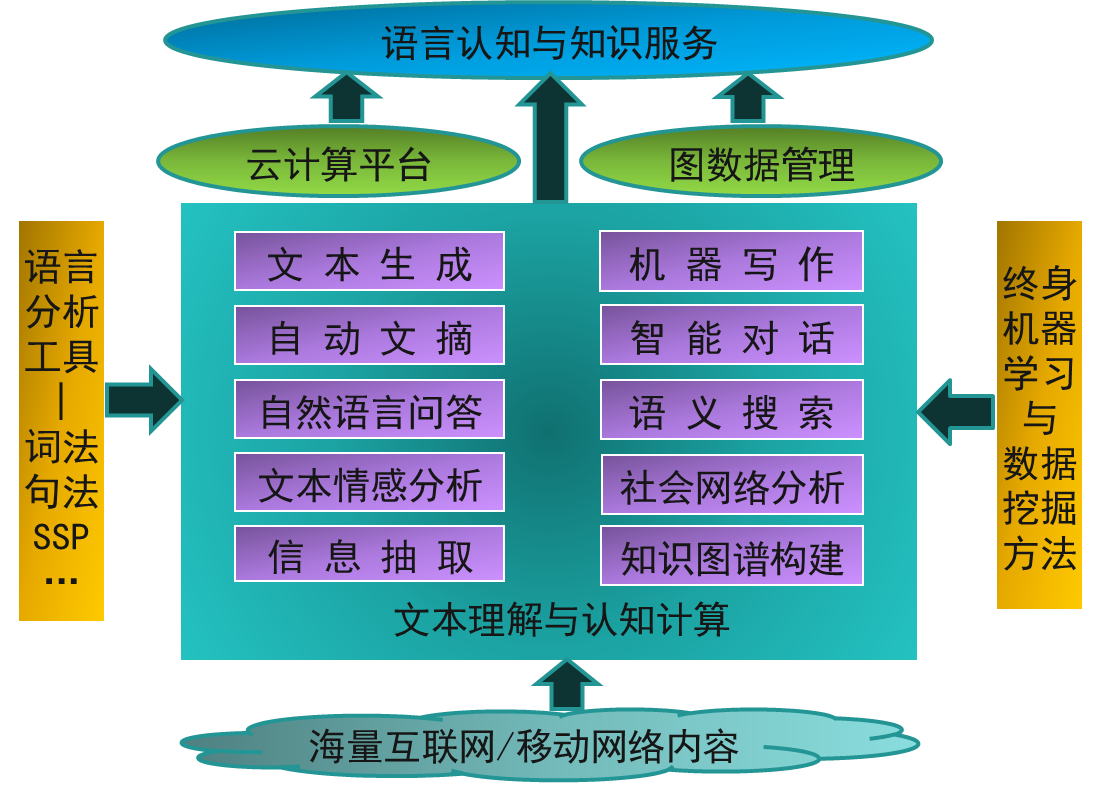
研究方向
认知计算与知识服务技术
|
|
|
王选所从20世纪80年代开始计算机网络与数据库技术的应用研究,1994年研制成功面向报社的新闻采编流程计算机管理系统,并在《深圳晚报》获得应用,此后历经12年持续研发和五代技术升级,成功研制“报业数字资产管理系统”,实现了中文报业“告别纸与笔”的技术变革,获2006年国家科技进步二等奖,推动了我国报业的技术进步。 2000年以来,随着互联网与人工智能技术的快速发展,新闻出版行业由数字出版、全媒体技术向自媒体、媒体融合和智能媒体技术演进。结合人工智能及媒体技术发展趋势,本方向开展了认知计算与知识服务技术的研发工作,已在ACL、AAAI、IJCAI、KDD、SIGMOD、VLDB、WWW、SIGIR、ICDE和TOIS、TKDE、VLDB Journal、Artificial Intelligence等CCF A类顶级会议与期刊上发表了100余篇学术论文,多次获得最佳论文及杰出论文奖,在美国NIST组织的文本推理评测、文档自动摘要评测、TREC微博检索评测,日本NII组织的中文文本情感分析评测,欧盟组织的知识库智能问答评测等任务上曾获得多次第一名,承担了20余项自然科学基金重点、国家重点研发计划、2030新一代人工智能重大研究计划等国家级项目,获授权专利数十项,gStore图数据库系统、新闻写作机器人、问道知识云等多项成果已获得应用。 目前认知计算与知识服务技术研究方向主要是以自然语言处理、机器学习与数据管理的基础研究基础,面向开放域、多语种和异质的海量数字内容,开展文本语义分析、自然语言生成、终身机器学习(Life-long Learning)、图数据管理等文本理解与认知计算技术的研究,为自然语言理解、社会网络计算、大规模语义数据管理与知识服务应用提供关键技术支撑。 主要研究内容: · 终身学习与开放式机器学习:研究终身学习和持续学习理论及其在自然语言处理中的应用,如对话系统中的持续学习等。研究开放式机器学习理论,实现在具有未知概念与不断演进的真实世界背景下的机器学习任务。 · 中文语言分析技术:包括中文词法分析、句法分析与浅层语义分析等基础技术,并开发可实用的中文语言分析工具。 · 自动文摘与文本生成:研究多类型自动文摘与文本自动生成方法,实现内容可控、长短可控、情感可控、风格可控的多类文本稿件(包括短摘要、新闻、综述、评论、诗歌等)的自动生成,并开展行业应用。 · 情感分析与观点挖掘:结合机器学习理论和自然语言处理方法,研究文本情感分析与观点挖掘技术,实现持续性学习机制,在社交媒体和电子商业等应用领域开展应用技术研发。 · 图数据管理:基于图的知识图谱数据管理技术研究,包括基于图的方法设计面向海量知识图谱数据的平台系统和高效查询算法和查询优化机制,面向知识图谱的自然语言问答和交互式检索系统等,并开展行业应用。
具有重要学术影响力的研究成果: · 在自动文摘领域,关于新闻短摘要生成的论文获得ACL 2017杰出论文奖(Outstanding Paper Award)。 · 在文本生成领域,关于情感文本生成的论文获得IJCAI 2018杰出论文奖(Distinguished Paper Award)。 · 在图数据管理领域,关于图数据查询方法的论文获得DASFAA 2018最佳论文奖。 已获得应用的主要科研成果: · 报业数字资产管理系统 报业数字资产管理系统实现了新闻媒体采编生产与经营管理的数字化、网络化及全流程一体化,应用于全球500多家中文报社、新闻通讯社,市场占有率80%,获2006年国家科技进步二等奖。 · 互联网舆情分析预警系统 该系统采用实时采集、自动抽取、主题检测和海量检索技术实现了互联网内容的自动获取、实时监控和强大的舆情信息处理功能,应用于多个省市、国家重要部门,为互联网舆情研判、掌握网络民意和打击网络低俗文化提供了智能化辅助手段。 · 数字报刊与跨媒体出版系统 该系统包含了版面标引加工、数字报刊制作、多渠道发布、自动上载、数字发行控制与多终端阅读等系列数字出版技术,实现了数字报刊生产自动化、内容交换规范化和运营模式多样化,已有近千份报刊采用该系统发布数字报刊,推动了我国报业数字出版技术的发展。 · 大规模知识图谱数据管理与查询系统——gStore 自主研发的面向RDF知识图谱数据的gStore图数据库系统,实现了以子图匹配的方法来构建面向RDF的查询机制。该系统目前可在百亿级RDF三元组知识数据的规模下达到秒级查询速度,分布式系统具有良好的可扩展性,2017年获得教育部自然科学二等奖(获奖项目名称:“大规模图结构数据管理”)。目前gStore系统在开源社区获得国内外广泛关注,并已经应用到多项企、事业单位的知识图谱项目中。 · 新闻写作机器人 研制的新闻写作机器人能够以原创和二次创作的方式撰写长短可控、跨领域的各类新闻稿件。小明、小南、小柯等多款写作机器人分别应用于字节跳动、南方都市报、科学网等单位,已自动撰写各类新闻稿件十万多篇,有效节约了成本,大大提高了写稿效率与覆盖率,受到一百多家国内外媒体报道。 · 大规模中文知识图谱——PKUBase 自主研制了知识图谱构建技术,并构建了大规模中文知识图谱PKUBase。 PKUBase采用了700多个概念分类的知识基础框架,包括类别概念10万个、类别信息300万条。PKUBase包含了高质量中文实体1300万,高质量事实性知识条目5500多万事。知识图谱构建技术和PKUBase已应用于多家企事业单位。 · 智能问答系统——“问道”知识云 “问道”知识云基于自主研制的通用中文预训练模型LatticeBERT、专用概念语义表示模型及知识图谱构建技术和gStore系统创建了习近平原文知识库,实现知识库和原文的全自动智能知识标注与知识关联。其中,基于语义理解的智能问答技术突破了思想知识问答任务的问题意图识别、自然语言问句理解和隐式知识关联分析等难题,首次实现了基于自然语言的智能思想理论问答技术——不依赖关键词就可以回答习近平经济思想的有关概念、措施和意义等问题,提供相关的理论知识内容。 |