北京大学王选计算机研究所IGCL实验室成员参加ECCV2024
2024年9月28日至10月4日,第18届欧洲计算机视觉会议(ECCV 2024)在意大利米兰举行。作为计算机视觉领域的顶级会议之一,ECCV与CVPR和ICCV齐名。本次会议共收到8585篇投稿,经过严格评审,有2395篇文章被录用,录用率为27.9%。

ECCV2024主会场
北京大学王选计算机研究所IGCL实验室发表的《UDiffText: A Unified Framework for High-quality Text Synthesis in Arbitrary Images via Character-aware Diffusion Models》被本届ECCV录用。

实验室硕士生赵一鸣作海报展示
该论文提出了一种名为UDiffText的高质量文字合成方法,能够在任意图像中合成高准确度且风格一致的任意英文文字。近年来,基于扩散模型的文本到图像(Text-to-Image, T2I)生成方法被广泛研究并取得一系列进展。尽管现有的图像生成方法能够产生高质量的输出,但图像中的文本渲染问题仍待解决,常见的问题涉及文字缺失以及漏字错字等各种拼写错误。这些问题严重限制了基于扩散模型的文本图像生成方法的实际应用性能。
为了缓解该问题以利用先进的扩散模型进行任意文字合成,该论文利用预训练的扩散模型(例如Stable Diffusion),通过设计和训练一个轻量级的字符级文本编码器替代原始的CLIP编码器,并提供更强大的文本嵌入作为条件指导。该方法在大规模数据集上微调扩散模型,并在字符级分割图的监督下进行局部注意力控制。最后,通过在推理阶段的细化过程,在合成任意给定图像中的文本时实现了显著的字符序列精度。
该论文在多个真实场景文字图像数据集上进行了定性与定量实验。实验结果显示,该方法在所有定量指标上都优于基线方法,该结果表明该论文提出的模型能够仅根据文本标签生成序列精度和质量更高的文本图像。在定性结果方面,该论文展示了上述相关方法在场景文本编辑任务中的输出结果。其中该方法产生了视觉上最令人满意的结果,具体表现在文字渲染准确度高,且视觉上下文连贯。此外,该方法在场景文本编辑,任意文本生成,文生图模型错误图像修复等任务上有一定的应用前景。
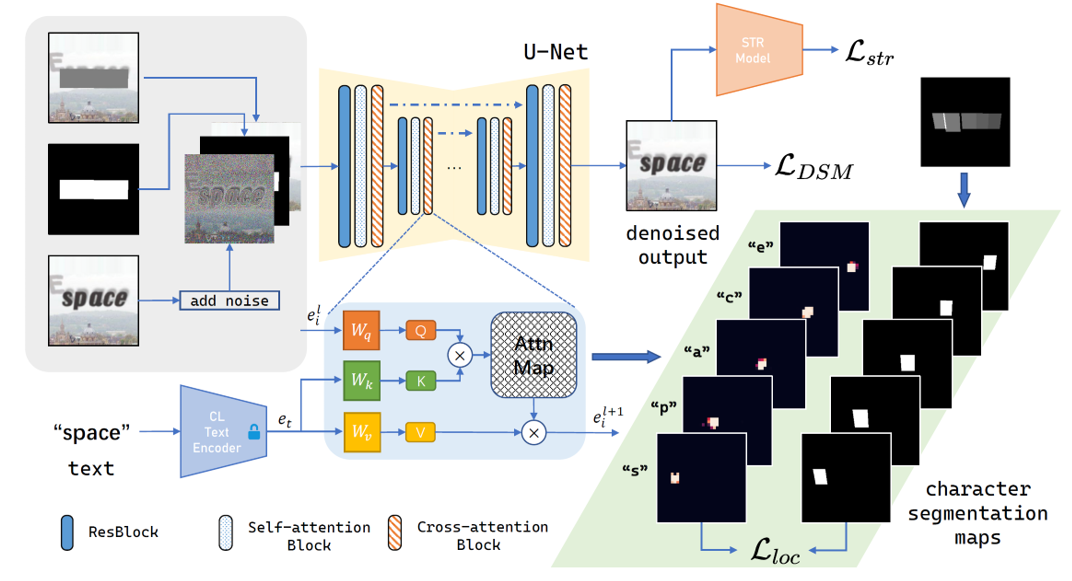
UDiffText整体框架
通过参加ECCV 2024,学生们不仅了解了计算机视觉领域的前沿研究成果,还在与业内人士的互动中掌握了实践中的需求和挑战,为实验室成员带来了许多宝贵的灵感和思路。
上一篇 下一篇