王选所机器智能实验室参加ECCV 2024
2024年9月28日至10月4日,欧洲计算机视觉国际会议(European Conference on Computer Vision, ECCV)于意大利米兰召开。王选所机器智能实验室的博士研究生金阳和硕士研究生马康淇参加了此次会议。
 |
 |
 |
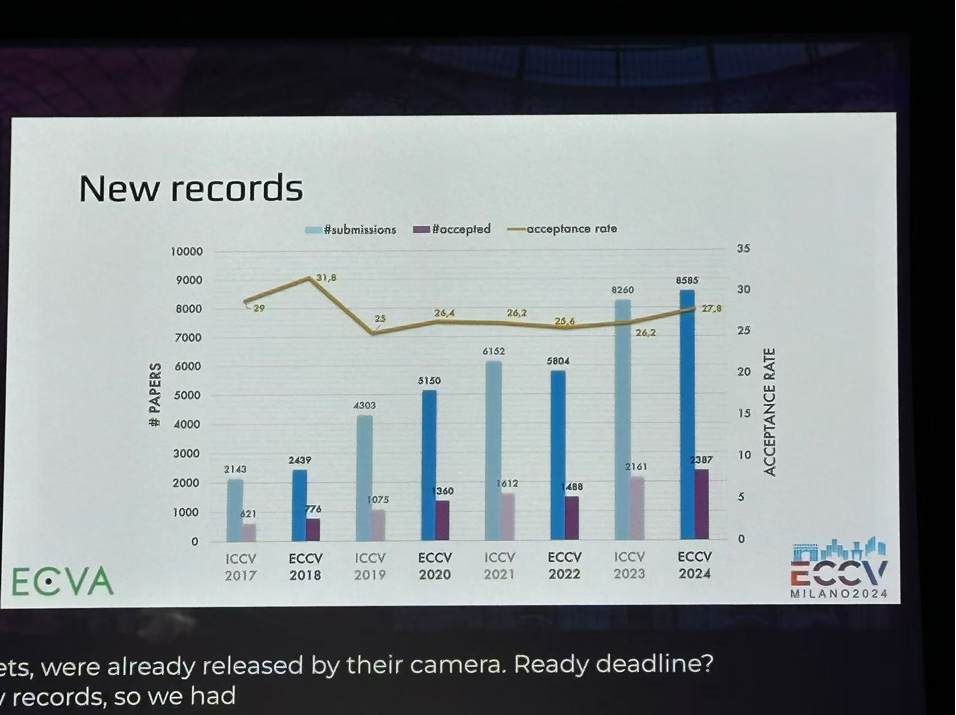 |
ECCV是计算机视觉领域的国际顶级会议。本次会议吸引了来自学术界、工业界研究者们参加。会议包括受邀演讲、口头报告、poster展示、workshop展示、业界技术宣讲等环节。本次大会共提交了8585篇论文,录取了其中2395篇,录取率为27.8%。王选所机器智能实验室师生在本次ECCV会议中总共发表两篇论文,接收的论文信息如下:
(一)Yang Jin, Yadong Mu, "Weakly-Supervised Spatio-Temporal Video Grounding with Variational Cross-Modal Alignment", ECCV 2024
视频中的视觉语言时空定位任务(STVG),需要对给定的文本从未剪辑的视频中进行定位出描述的物体。现有的方法主要依赖于的人工标注作为监督信息,进行训练,这种范式严重限制了模型在大规模未标记数据上的可扩展性。为此,我们提出了一种新的弱监督视频定位框架,能够仅依靠视频与文本之间的弱对应关系来定位目标对象。具体来说,我们的模型将原始的STVG任务重新建模为两个跨模态对齐的子问题,并将其视为可学习的隐变量,通过重建视频中实体之间的交互关系来学习目标匹配的联合条件分布。整个框架可以通过变分期望最大化(EM)算法有效优化。我们的模型在两个视频定位基准数据集(VidSTG和HC-STVG)上的进行了大量实验验证,相比以往的方法取得了较大的提升。
(二)Kangqi Ma, Hao Dong, Yadong Mu, “Local Occupancy-Enhanced Object Grasping with Multiple Triplanar Projection”, ECCV 2024
近期基于视觉的智能抓取系统都依赖于对单目深度相机捕获的点云进行特征学习来预测抓取位姿。然而,由于单目点云不能完整表示场景形状信息,导致在高度遮挡场景下,抓取模型经常出现不准确和高碰撞风险的预测。在本文中,我们提出了使用3D Occupancy对抓取点进行局部填充来恢复局部大致形状信息,另模型进一步理解场景关系,减少碰撞风险。根据抓取任务特点,本文提出了multi-group tri-plane结构进行场景表达,有效将occupancy预测限制在较小的关注区域内,大幅减少了3D特征的学习代价。经过局部occupancy增强,本文方法在benchmark和真实场景测试中,抓取成功率都较先前方法取得了明显提升。
通过这次会议,王选所机器智能实验室的同学与国际计算机视觉领域的科研人员和企业进行了交流和讨论,进一步了解了前沿发展方向和技术挑战,为实验室接下来的研究提供了经验和思路。
上一篇 下一篇